
2주차를 마무리했다.
본격적으로 알고리즘 주차가 시작된거같다. 백준 플레티넘 문제는 처음보는데 문제를 이해하는데 3시간
구현 할 엄두 조차 안나서 풀이를 보고도 이해하는데 5시간 거의 하루종일 한 문제만 잡고 있었다.
1주차에 붙혔던 재미가 다 나가떨어지는
이렇게까지 알고리즘 하나 풀어보겠다고 몰두해본 경험이 없는거같은데 이렇게 몰입하고 고민했던 문제들은
정말 글을 쓰는 지금도 기억이 남을정도로 강렬한 맛이다. 좋은거 같아요 👍
이번주 키워드
이분탐색 - 이분 탐색이란 데이터가 정렬되있는 배열에서 특정한값을 찾아내는 알고리즘이다.
중간에 있는 임의의 중간값을 찾고자하는 값 X와 비교하여 X가 중간값보다 작을땐 중간을 기준으로 좌측의 데이터를 탐색
중간값보다 클땐 우측의 데이터를 탐색 반복한다.(종료조건은 원하는 값을 찾았을때 or 원하는 값이 배열에 존재하지 않을때이다)
반복문과 재귀함수로 구현할수있다.
시간 복잡도는 O(log N)이다
분할정복 - 그대로 해결할 수 없는 문제를 작은 문제로 분할해서 문제를 해결하는 알고리즘이다.
분할 정복 설계 방법
1) Divide(분할)
원래 문제가 분할하여 비슷한 유형의 더 작은 하위 문제로 분할이 가능할 때 까지 나눈다.
2) Conquer(정복)
각 하위 문제를 재귀적으로 해결. 더이상 하위 문제의 규모가 나눌 수 없으면 종료 조건 설정한다.
3) Combine(결합)
정복한 하위 문제들을 결합하여 문제 해결
중요 - 분할을 제대로 나누면 정복 과정은 자동으로 쉬워진다. 분할 설계를 잘하는 것이 중요함, 재귀적으로 해결하기 때문에
정복과정에서 알고리즘의 효율성을 떨어뜨릴수있다.
스택 - 스택처럼 쌓아올리는 선입후출 후입선출 자료구조이다 ex) 하노이 탑, 뒤로가기, 실행취소 등
중간에 있는거 못뺌
큐 - 먼저 들어간 데이터가 먼저 나오는 선입선출 자료구조이다 ex) 은행 창구, 줄서기
오로지 한쪽에선 삽입(rear)만 한쪽에선 출력(front)만 가능하다. 각자 삽입할수록 출력할수록 값이 증가한다.
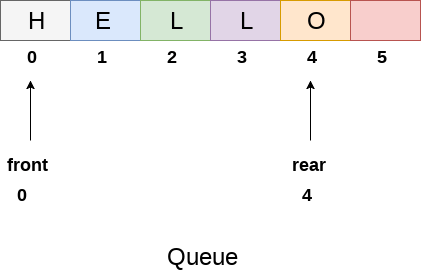
우선순위 큐 - 일반적으로 선입선출의 구조인 큐와 달리 가장 작은 값을 먼저 출력하는 자료구조로 내부적으로 heapq를 이용해 정렬된 상태로 보관한다.
링크드 리스트 - 먼저 리스트는 데이터를 순서대로 나열한 자료구조로 대표적으로 스택, 큐가 리스트형태의 자료구조인데
배열로 구성된 자료구조는 쌓이는 데이터의 크기를 미리 알아야한다는 것, 데이터를 중간에 삽입, 삭제에 따라 전부 옮겨야되기때문에 효율이 좋지않다. 따라서 이러한 단점들을 보완하기위해 노드(데이터와 다음 노드 위치를 나타내는 포인터를 저장하고있는 객체)와 포인터의 개념을 이용한게 링크드 리스트이다.
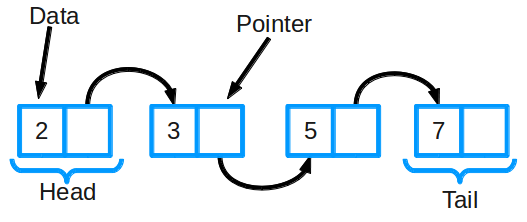
이와 같이 삽입, 삭제가 일어날경우 해당 포인터에 저장된 다음노드의 위치만 변경해주면 되기때문에
배열로 되어있는 리스트보다 더 효율적이다.

'WIL' 카테고리의 다른 글
| 크래프톤 정글 2기 5~7주차 후기 (1) | 2023.06.09 |
|---|---|
| 크래프톤 정글 2기 4주차 후기 (1) | 2023.05.10 |
| 크래프톤 정글 2기 3주차 후기 (0) | 2023.05.02 |
| 크래프톤 정글 2기 1주차 후기 (0) | 2023.04.19 |
| 크래프톤 정글 2기 0주차 후기 (0) | 2023.04.11 |